Applied AI Engineer / Backend Lead
Python · OpenAI SDK · Next.js · GCP · Firebase · Algolia · Node.js · recall.ai
200,000+ leads indexed · Production platform · IPO-stage company
5× per-lead processing improvement · Large batches from 2–3 hrs to 15–20 min · Multi-stage meeting ingestion agent shipped
Context
Pathos is an AI-driven PR platform used by a firm serving thousands of customers. I joined when the system was a Streamlit proof of concept built by a previous developer — a working demo that generated PR angles from public data using LLMs, with no authentication layer, hardcoded prompts, and no architecture designed for production use. Within months, the tool began evolving into a client-facing platform serving real customers. I was responsible for the frontend throughout and took on identifying and resolving technical problems across the backend as they emerged. At various points I managed a junior developer, and I made architectural and engineering decisions under delivery pressure and a frequently incomplete specification. I was part of the team through the company's IPO.
The Problem
Three structural risks were converging simultaneously. The Streamlit frontend was unsuitable for a client-facing application at scale. The backend lacked separation of concerns, making iteration increasingly slow and fragile. And the core entity — the "Newshook", the platform's primary output — was being redefined mid-production: what began as a PR angle derived from a person's background expanded to include lead activity, contextual trends, and business signals. The entity changed while already in use. Without structural intervention, the platform would have become unusable under continued growth.
Architectural Reset
Migrated the frontend entirely from Streamlit to Next.js — the frontend was my full responsibility throughout the project. The migration was not incremental; I rebuilt the client from scratch to establish a foundation suited for production.
Introduced Firebase authentication and restructured backend service boundaries. Replaced hardcoded prompts with structured prompt construction. Added retry logic, rate-limit handling, and baseline testing. The goal was not to add features — it was to create an architecture that could tolerate ongoing ambiguity and iteration.
Stabilised the Newshook ontology as it evolved. When the definition of the platform's core concept expanded mid-production, I adapted the data model and client-side representation to accommodate the new scope without halting development.

Ontology Drift
The Newshook was the central artifact of the product — what the system produced and what clients consumed. In the PoC, it existed as a loosely structured dictionary. As the product scaled, different parts of the codebase developed divergent assumptions about what a Newshook contained, how it was identified, and what operations could be performed on it. Formalising the schema required auditing every place where Newshook assumptions were encoded — and then managing the transition across the frontend, backend services, and downstream integrations simultaneously in a live system. In applied AI systems, ontology stability is a first-class engineering concern. The entities your system produces need to be defined with the same rigour as your API contracts, and that rigour must be established before usage patterns cement implicit assumptions into structural debt.
Scaling the Pipeline
As the platform matured, performance became the constraint. Early bulk processing required approximately 5 minutes per lead. I identified the bottlenecks, restructured the prompt workflows, and introduced concurrency. Processing time dropped to under 1 minute per lead. Large batches that previously required 2–3 hours could be processed in 15–20 minutes. This required separating enrichment tasks from generation tasks, managing OpenAI token usage at scale, handling rate limits predictably, and translating raw transcripts into LLM-efficient representations. I also built search indexing via Algolia across approximately 200,000 leads and contributed to pipeline infrastructure for bulk ingestion.

Model Discipline
The platform generated content for real PR clients. The approach to output reliability was architectural rather than prompting-focused. Most hallucination in production AI systems comes not from model weakness but from task ambiguity — asking the model to operate within a scope that hasn't been precisely defined. Task decomposition reduced the failure surface per inference call. Constraint enforcement at the schema level caught malformed outputs before they reached the client layer. Applied AI systems need to be engineered to fail gracefully on bad outputs: constrain surface area through task decomposition, validate at boundaries through schema enforcement, and design the rejection path so failures are contained rather than propagated.
Pressella
In parallel with the core platform, I architected Pressella from scratch — a meeting ingestion agent built on recall.ai. Pressella joined sales calls, captured transcripts, enriched them with external context, and generated customised follow-up articles and emails. I designed the pipeline as a sequence of distinct LLM calls rather than a single monolithic prompt: transcript preprocessing, context enrichment, article angle generation, article drafting, and email synthesis with conditional emphasis. A post-call feedback layer was introduced, allowing salespeople to provide structured input after the meeting that shaped the generated output. Reliability was the primary design constraint — the system was architected from scratch with that priority, not retrofitted.
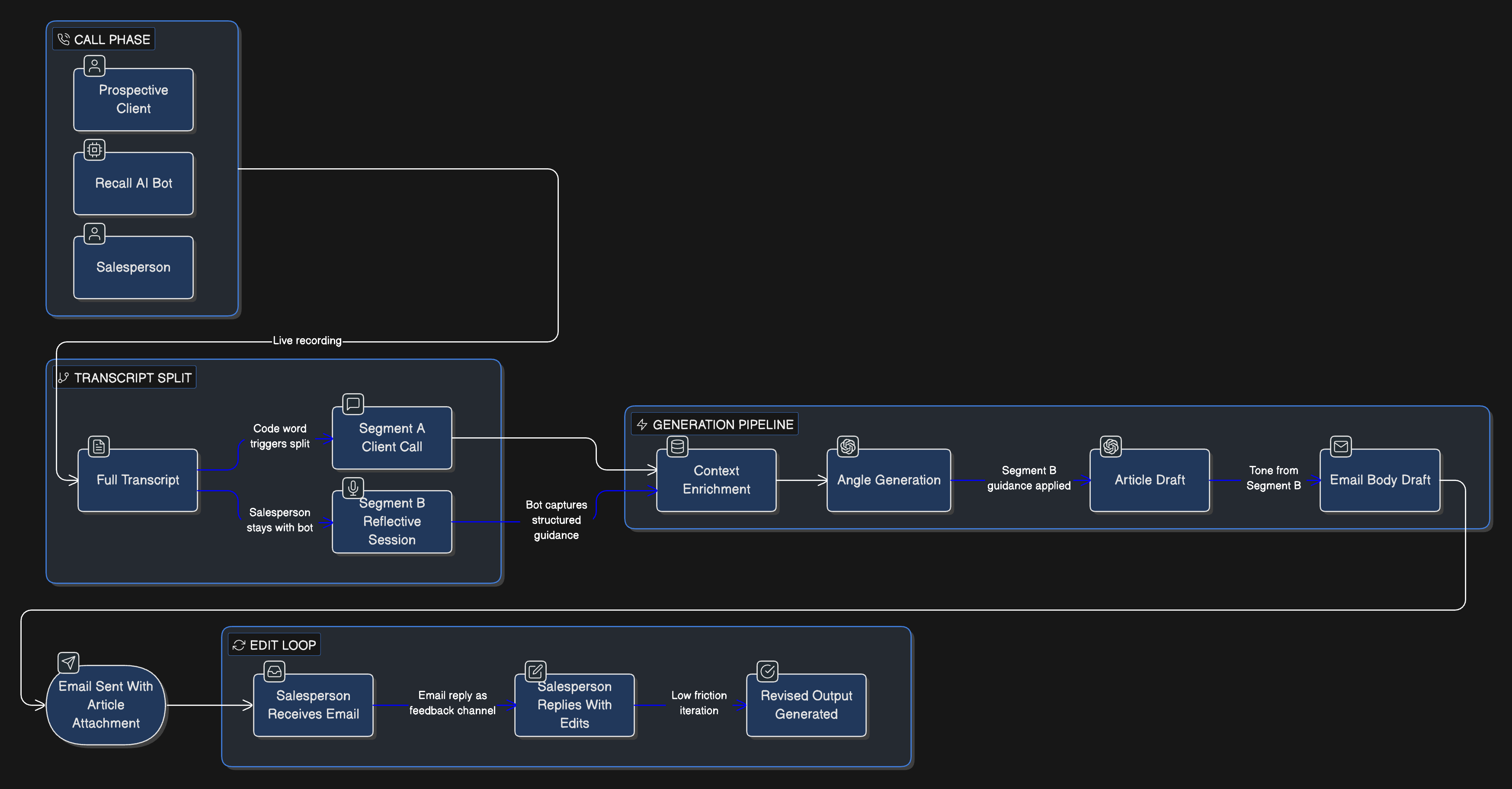
Tradeoffs & Failures
Not everything worked. Pressella failed Zoom Marketplace review due to a production configuration mismatch — the system functioned correctly in development but did not meet the deployment environment's compliance requirements. I adjusted the configuration flows, security posture, and production validation process. On bulk processing infrastructure, some solutions were pragmatic rather than elegant — distributed execution under time pressure. Governance and alerting matured more slowly than core functionality. That was a deliberate tradeoff given team size and delivery constraints, though earlier investment in monitoring would have reduced operational friction. Scope discipline was also a constant: protecting architectural boundaries required saying no to ideas that added novelty at the cost of stability.
Outcomes
- Platform cited as a proprietary technology asset in Pathos' AIM admission documentation.
- Per-lead processing time reduced from ~5 minutes to under 1 minute; large batch jobs from 2–3 hours to 15–20 minutes.
- Pressella operating as a structured ingestion layer within the full ecosystem.
- Auth, user management, and backend services stable under production load.
- ~200,000 leads indexed in Algolia across the platform's CRM-like workflows.
Lessons
Proof of concepts rarely survive production without structural redesign.
Applied AI systems fail more often from boundary ambiguity than model weakness.
Ontologies stabilise through usage, not whiteboarding — define schemas with API-contract rigour.
Architecture must anticipate iteration velocity — ambiguity is an operating condition, not a blocker.
IPO
IPO Day

Pathos Communications celebrates its AIM admission at the London Stock Exchange — December 2025.

PATHOS COMM debuts on AIM at 30p — London Stock Exchange trading floor, 16 December 2025.