Solo Full-Stack Engineer — mobile, backend endpoints, database architecture, App Store deployment
React Native · Expo EAS · Google Cloud Platform · Firebase · Node.js · Twilio
5,000+ low-income families · $500K U.S. Department of Education grant · Active longitudinal study
Rearchitected date-anchored content delivery into a versioned, multi-cohort research platform supporting parallel teacher cohorts and longitudinal data integrity
What is Chat2Learn?
Context
Chat2Learn is a mobile platform developed by the Behavioral Insights and Parenting Lab at the University of Chicago. It has served 5,000+ low-income families across Illinois and was validated through a randomised trial of over 700 families with near-zero dropout rates. A $500K U.S. Department of Education grant expanded the program into pre-K and kindergarten classrooms — introducing teachers as an entirely new user class with no existing architecture to support them. I joined in the earlier phase implementing frontend views and integrating Twilio-based SMS authentication. The second phase — the teacher expansion — was mine entirely: sole full-stack engineer across mobile, backend endpoints, database architecture, and App Store deployment.
The Problem
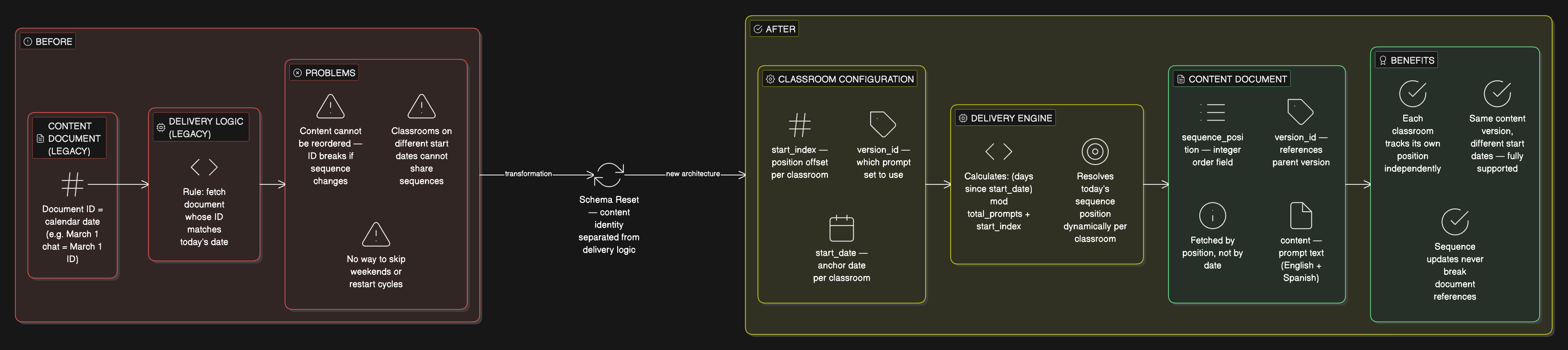
The system was architected around parents. Every assumption — how users enrolled, how content was scheduled, how authentication was scoped — reflected a single user type, encoded structurally rather than as configuration. The most concrete failure: chats were stored with date-anchored document IDs, making content unorderable, cohort-incompatible, and brittle against any scheduling change. Cohorts starting on different dates could not share the same content sequence. The system had no mechanism to express concepts like "skip weekends" or "repeat a cycle." The teacher expansion required rethinking all of this — without a complete specification in place at the start.
Architectural Reset
Decoupled content identity from calendar identity. Restructured Firestore collections so chats are identified by position in a sequence, not a fixed date. The delivery engine resolves "today's chat" dynamically: given a cohort's anchor date and offset, it computes the current sequence position and retrieves the corresponding document.
Applied the same restructuring to the "More Chats" bucket — a secondary collection of 40–80 alternative chats stored in a form making reordering and filtering difficult. Gave the research team the ability to adjust content without touching core documents.
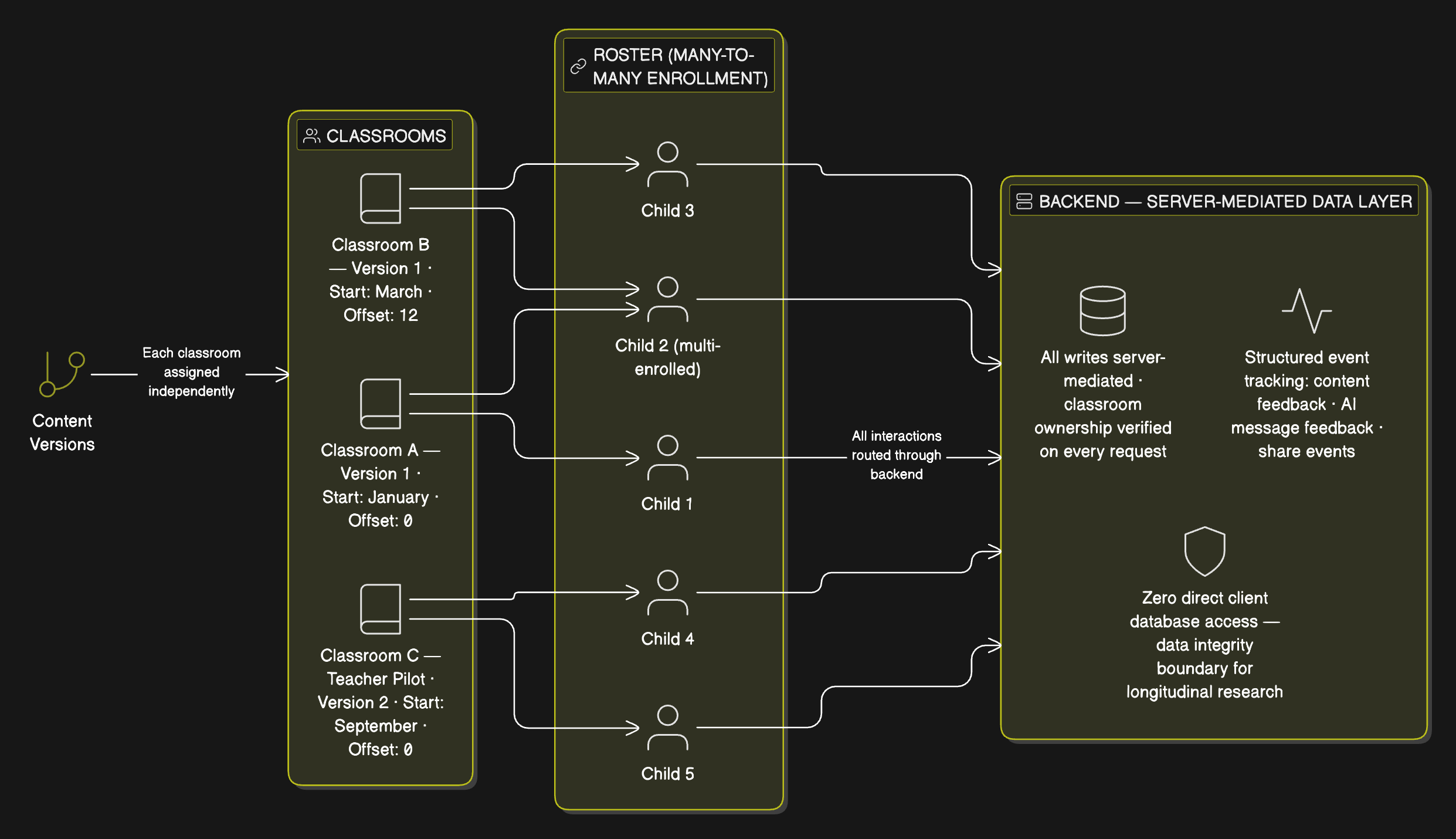
Introduced the teacher entity into the Firestore schema: teacher–classroom relationships, a closed enrollment model for a restricted research cohort, and backend-mediated writes with no direct client Firestore access — a deliberate data-integrity boundary for a longitudinal dataset where client-side writes would create audit and consistency risks.
Managing Ambiguity
The teacher study began with an incomplete specification. The client knew they wanted a closed system — only a select group of teachers would have access — but could not provide the list of teachers, their emails, or how classroom membership would be structured at the point when architectural decisions needed to be made. Several questions remained open well into development: how teachers would be enrolled, who created classrooms, what the relationship was between a teacher's classroom and the parent accounts already in the system. Each had architectural implications that couldn't easily be reversed once the study began accumulating data. My approach was to design for configurability rather than assumption — building the schema to accommodate multiple valid answers rather than hardcoding one. I surfaced technical questions as they had practical stakes, framing them in terms the research team could act on: "if we don't define this before pilot launch, changing it later means a schema migration during an active study."
Multi-Cohort Research
A research study is not a single-user product. The versioned scheduling architecture I designed supports multiple simultaneous cohorts running concurrently without shared mutable state between them. Each cohort maintains its own position in its assigned content sequence. The research team can adjust which sequence a cohort receives, modify sequence content, or introduce new teacher groups without requiring changes to the core delivery logic. Interaction tracking was added at a granular level — chat opens, completions, and shares captured as structured events rather than aggregate counters, preserving the data quality the team needs for study analysis.
Deployment & Ownership
Beyond the application itself, I owned the full deployment pipeline: configuring Expo Application Services, managing certificates and provisioning profiles for App Store Connect, and publishing test builds to TestFlight on behalf of the University of Chicago. Publishing under an institutional Apple Developer account introduced operational complexity that pure development work doesn't. The university had an existing EAS setup from the parent study with its own certificates and permissions — gaining access and publishing under their account required navigating institutional processes alongside technical ones. A deployment error during an active study phase affects data collection. This shaped my approach to release management — careful staging, TestFlight validation with internal users before broader pilot access, and direct communication with the research team about build timelines and known issues.
Outcomes
- Platform supports multiple simultaneous research cohorts without shared mutable state.
- Schema is now a configurable platform — content, cohort start dates, teacher groups, and interaction metrics can all be adjusted without engineering changes to the core delivery logic.
- Near-zero dropout rates maintained from the original validated trial.
- Teacher pilot launched on schedule for an active longitudinal study.
- Research efficacy data remains with the BIP Lab team — the study is ongoing.
Lessons
Research context software requires schema stability above all else — surface architectural questions before data accumulates, not after.
Date-anchored identifiers are hardcoded business logic. Content identity and scheduling logic must be separated from the start.
Ambiguity in stakeholder requirements is an engineering constraint. Design for configurability; defer commitment to specifics until they're actually available.
Operational ownership — deployments, certificates, TestFlight — carries the same stakes as architecture when the system is running a live study.